I help companies build RAG systems they can trust in production.
Retrieval quality, hallucination control, ranking, observability, and deployment architecture for internal AI assistants, enterprise search, support automation, and production LLM workflows.
Most RAG systems fail because retrieval is treated like a checkbox.
A vector database does not make an LLM trustworthy. Production RAG requires deliberate decisions across ingestion, chunking, embeddings, ranking, prompt assembly, fallback behavior, and evaluation.
The system retrieves something, but not the right thing.
Top-k similarity is not enough when the corpus has overlapping policies, outdated PDFs, duplicate product pages, or support articles with near-identical language.
Chunks are optimized for storage, not answer quality.
Arbitrary chunk sizes destroy context, split procedures across boundaries, bury metadata, and force the model to infer relationships the retrieval layer should have preserved.
The LLM is allowed to answer around the retrieval layer.
If the system can respond from parametric knowledge when retrieval is weak, hallucinations become a product behavior instead of an exception path.
There is no measurement loop.
Without golden questions, retrieval traces, confidence signals, failed-query logs, and answer evaluation, teams argue from anecdotes instead of improving the system.
The failure modes are usually architectural, not model-related.
Using one vector index for content with different freshness, risk, and query patterns.
Embedding raw documents without canonicalization, metadata normalization, or stale-content controls.
Choosing embedding models by price alone instead of retrieval accuracy on representative queries.
Skipping hybrid search, metadata filtering, reranking, or query rewriting when the corpus requires it.
Stuffing retrieved chunks into the prompt without context budgeting, source ordering, or conflict handling.
Deploying without retrieval observability, human escalation, regression tests, or a feedback loop for unknowns.
I work on the parts of RAG that decide whether users trust it.
Retrieval strategy
Query routing, index separation, hybrid retrieval, metadata filters, freshness controls, and search patterns aligned with how users actually ask questions.
Chunking strategy
Document-aware chunking that preserves procedures, product relationships, headings, policy scope, source metadata, and answerable units of knowledge.
Embedding decisions
Embedding model selection, dimension trade-offs, multilingual considerations, cost controls, and evaluation against real query sets before production rollout.
Vector database architecture
Index design, namespace strategy, metadata schema, update pipelines, deletion behavior, re-embedding plans, and vendor trade-offs for production operations.
Ranking and reranking
Reranker integration, score thresholds, result diversification, conflict detection, and ordering rules that favor grounded answers over plausible noise.
Context optimization
Prompt assembly, context compression, source citation strategy, token budgeting, model routing, and rules for when the system must refuse or escalate.
Hallucination prevention
Grounding rules, mandatory retrieval paths, answer validation, confidence thresholds, safe fallback responses, and human-in-the-loop escalation for risky queries.
Observability and evaluation
Retrieval logs, trace inspection, golden datasets, answer-quality scoring, unanswered-question loops, and regression tests for prompt, model, or corpus changes.
Production deployment strategy
Latency budgets, cost modeling, caching, rate-limit handling, rollout plans, monitoring, runbooks, and documentation your team can maintain after handoff.
Engagements for teams building or rescuing production RAG.
I do not sell generic AI roadmaps. I work with teams that already know RAG matters and need the architecture to make it reliable.
RAG Architecture Review
A structured review of your retrieval pipeline, vector database design, prompts, failure modes, and observability. You get a written diagnosis and prioritized remediation plan.
- ->Retrieval and vector architecture review
- ->Chunking, embedding, and ranking assessment
- ->Hallucination and fallback risk analysis
- ->Written report with prioritized fixes
Enterprise RAG System Design
Architecture for a new internal assistant, enterprise search layer, support automation workflow, or knowledge system before implementation locks in the wrong assumptions.
- ->Reference architecture and data flow
- ->Index, metadata, and ingestion design
- ->Evaluation plan and acceptance criteria
- ->Implementation backlog for your team
RAG System Rescue
For systems already returning irrelevant answers, hallucinating, timing out, or losing stakeholder trust. I isolate the root causes and stabilize the retrieval path.
- ->Failure-mode diagnosis
- ->Immediate stabilization recommendations
- ->Retrieval and prompt remediation plan
- ->Optional hands-on implementation
Fractional LLM Architecture Advisory
Ongoing senior guidance for teams shipping RAG and LLM systems: architecture decisions, model/vendor evaluation, design reviews, and production-readiness checks.
- ->Weekly architecture guidance
- ->Async review of technical decisions
- ->Vendor and model trade-off support
- ->Production readiness reviews
A review should produce decisions, not a vague list of concerns.
The goal is to identify why the system is failing, what needs to change, and which changes matter first. That means looking at the data path, not only the prompt.
Corpus and use-case mapping
We map the documents, data sources, update cadence, risk level, user intents, and the answer types the system must support or refuse.
Retrieval trace analysis
I inspect real queries, retrieved chunks, scores, filters, reranking behavior, prompt assembly, and cases where the model answered without enough evidence.
Architecture recommendations
You get concrete decisions on chunking, embeddings, indexes, metadata, ranking, observability, fallback behavior, and deployment strategy.
Implementation roadmap
The output is a prioritized plan your team can execute: immediate fixes, deeper refactors, evaluation gates, and production readiness requirements.
I have built RAG where wrong answers have consequences.
My RAG work comes from production systems: regulated product guidance, WooCommerce order lookups, HelpScout escalation, Pinecone retrieval, unanswered-question logging, and operational handoff.
Relevant work and writing

Production RAG support bot
A WooCommerce support agent with Pinecone retrieval, live order lookup, HelpScout escalation, and a 40% support ticket reduction.
Read more ->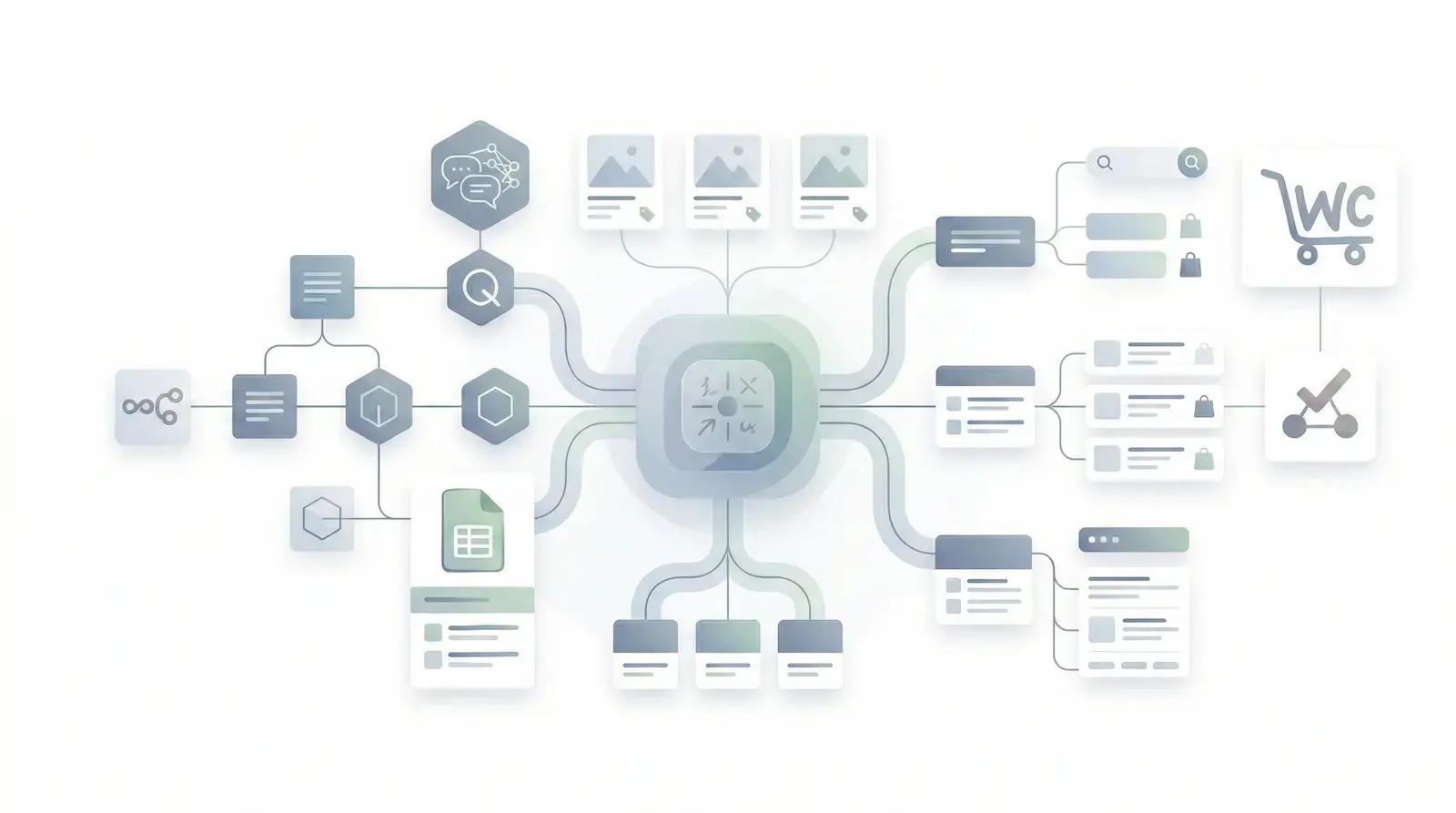
How I built a production RAG chatbot
A technical walkthrough of the index separation, mandatory retrieval path, tool workflows, and feedback loop behind the system.
Read more ->
Why AI projects fail after the demo
A breakdown of the gap between impressive pilots and systems that survive real data, rate limits, edge cases, and user trust.
Read more ->RAG consulting questions companies actually ask.
What does a RAG systems consultant do?
+
When should we bring in a RAG consultant?
+
Do you work with existing vector databases?
+
Can you help reduce hallucinations in a RAG system?
+
Do you implement or only advise?
+
What makes enterprise RAG different from a basic chatbot?
+
How long does a RAG architecture review take?
+
If your RAG system cannot be trusted, fix the architecture first.
Send me the current failure pattern: bad retrieval, hallucinations, irrelevant responses, low confidence, poor citations, latency, cost, or a failed internal assistant. I will tell you what I need to review and what a useful engagement would look like.
You speak directly with me. No sales team, no generic AI discovery script.